Note
Need help? Please let us know in the UMEP Community.
5.1. Benchmark System
- Contributor
Name
Institution
Ting Sun
Reading
Sue Grimmond
Reading
Fredrik Lindberg
Göteborg
- Overview
This plugin examines the differences between various datasets, e.g. two different model runs using the same input data but with different modell settings. The original version runs in a command-line interface (CLI) driven by Python and this GUI-based version is using the same code but connected to the interface.
The Benchmark System is originally designed for SUEWS but it can also be used for other data.
- Benchmark results
Two types of metrics are provided: 1. Overall performance score: a score between 0 and 100 with larger score denoting better overall performance. 2. Specific statistics: a range of statistics, including Mean absolute error (MAE), root mean square error (RMSE), standard deviation (Std), etc., to indicate detailed performance in specific variables.
The users can use the overall performance score to get the performance overview of all configurations (Fig. 1a) and specific statistics to examine the performance details (Fig. 1b).
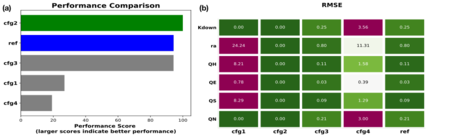
Fig. 5.1 Benchmarking results for (a) the overall performance and (b) a specific statistics (e.g., RMSE)
- Usage
To use plugin, the base file is e.g an observation dataset and reference dataset is a model run. Then a first comparison dataset is needed which could be a nother model version output. However, if you want to compare only two datasets, just use the same dataset as base and reference. It must be noted that the output files to be benchmarked should be of consistent temporal organisation (i.e., identical length and resolution) while the headers of different files are not necessarily to be identical as BSS will handle the header inconsistency automatically.
When you run the plugin, a namelist is created. THis can be re-used if you run the same setting again. This namelist can be found in the BenchMarking-folder in the UMEP plugin directory.
- Output
Output is save to a pdf which needs to be specified.